Welcome to Tracer’s Site!
The paper “Tracking Patches for Open Source Software Vulnerabilities” has been submitted to ESEC/FSE 2022. This page lists the supplementary materials that are omitted from the paper due to space limitations, (i.e., hidden patches in NVD, dataset, accuracy, sensitivity, and application analysis), and releases the experimental data.
Table of Contents
Tracer
Open source software (OSS) vulnerabilities threaten the security of software systems that use OSS. Vulnerability databases provide valuable information (e.g., vulnerable version and patch) to mitigate OSS vulnerabilities. There arises a growing concern about the information quality of vulnerability databases. However, it is unclear what the quality of patches in existing vulnerability databases is; and existing manual or heuristic-based approaches for patch tracking are either too expensive or too specific to apply to all OSS vulnerabilities.
To address these problems, we first conduct an empirical study to understand the quality and characteristics of patches for OSS vulnerabilities in two industrial vulnerability databases. Inspired by our study, we then propose the first automated approach, Tracer, to track patches for OSS vulnerabilities from multiple knowledge sources. Our evaluation has demonstrated that i) Tracer can track patches for up to 273.8% more vulnerabilities than heuristic-based approaches while achieving a higher F1-score by up to 116.8%; and ii) Tracer can complement industrial vulnerability databases. Our evaluation has also indicated the generality and practical usefulness of Tracer.
Experimental Data
Empirical Study
Breadth Dataset. We built a breadth dataset of OSS vulnerabilities by crawling all the OSS vulnerabilities from $DB_A$ and $DB_B$ as of April 7, 2020 by their publicly available interfaces. We obtained 8,630 and 5,858 CVEs from $DB_A$ and $DB_B$ respectively. $DB_A$ and $DB_B$ contain a union of 10,070 CVEs.
Depth Dataset. For each CVE, two of the authors separately found its patches by analyzing patches reported by the three databases, looking into CVE description and references in NVD, and searching GitHub repositories and Internet resources. When they had disagreements, a third author was involved into the discussion for consensuses. Finally, they successfully found patches for 1,295 CVEs,
Both Breadth Dataset and Depth Dataset can be found here.
Evaluation
Generality Evaluation. To evaluate the generality of Tracer to a wider range of OSS vulnerabilities, we construct two more datasets here.
Usefulness Evaluation. To evaluate the usefulness of Tracer in practice, we conducted a user study with 10 participants to find patches of 10 CVEs. The 10 tasks can be found here.
Supplementary Materials
These materials are omitted from the submitted paper due to space limitations, and the PDF document can be found here.
Dataset Analysis
We analyzed the 1,295 CVEs in our depth dataset with respect to years and programming languages. We determined the programming language of a CVE by analyzing the changed source files in patches. As shown in Fig.1a, the number of CVEs increases every year, which is consistent with Snyk’s report. As reported in Fig. 1b, these CVEs mainly cover seven programming languages, which demonstrates relatively good coverage of ecosystems. Therefore, we believe that our depth dataset is representative of OSS vulnerabilities.

Hidden Patches in NVD
In NVD, patches for a CVE might be listed in the references, and references might be tagged with “Patch”. Therefore, we manually find such hidden patches in NVD for our depth dataset. Specifically, we look for commit references in NVD’s references and manually confirm whether they are correct patches. We also look into the reference tagged with “Patch” to find patches that may be referenced by the tagged reference. In this way, we find patches for 540 of the 1,295 CVEs in our depth dataset, but fail to find any patch for 755 CVEs. On those 540 CVEs, our manual effort achieves a patch precision of 1.0, a patch recall of 0.816 and an F1-score of 0.862, which is similar to our first heuristic in RQ6 in the submitted paper.
It is worth mentioning that we do not include patch quality evaluation of NVD in our empirical study because i) NVD does not provide a “patch” field for CVEs, and ii) employing the above manual analysis to measure the patch quality of NVD would be unfair because it heavily depends on the manual effort and does not truly reflect the patch quality of NVD.
Accuracy Analysis
We analyzed the overlap between the patches identified by Tracer (denoted as $P_{Tracer}$) and our manually identified patches (denoted as $P_{GT}$ ) for each CVE in our depth dataset. In particular, we classify overlap relationships into six categories, which are used as another indicator of patch accuracy. The result is reported in Table 1, where the first column lists the six categories, the second column shows the number of CVEs belonging to each category, and the last column gives the total number of patches found by Tracer.
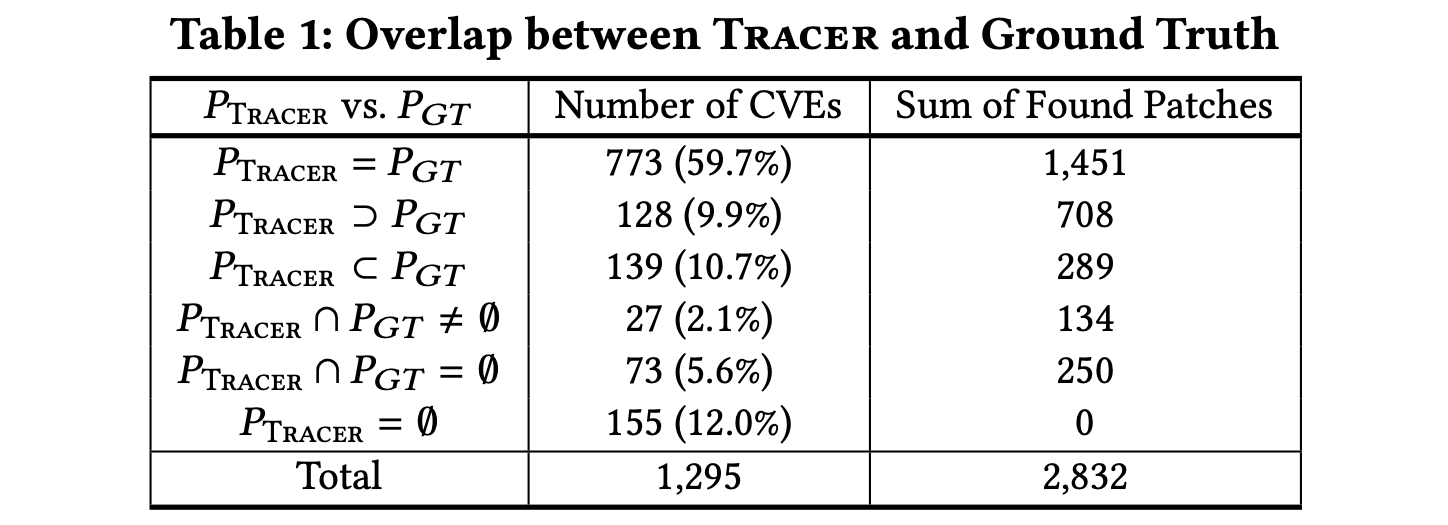
It can be observed that Tracer can find patches accurately and completely for 773 (59.7%) CVEs (i.e., $P_{Tracer} = P_{GT}$), with an average of 1.9 found patches for each CVE. Tracer can find patches completely but include some false positives for 128 (9.9%) CVEs (i.e., $P_{Tracer} ⊃ P_{GT}$). In that sense, 901 (69.6%) CVEs’ patches are completely found by Tracer. Besides, Tracer can find patches accurately but have some false negatives for 139 (10.7%) CVEs (i.e., $P_{Tracer} ⊂ P_{GT}$). Tracer incurs both false positives and false negatives for 27 (2.1%) CVEs (i.e., $P_{Tracer} ∩ P_{GT} \not= ∅$), while the patches found for 73 (5.6%) CVEs by Tracer are all false positives (i.e., $P_{Tracer} ∩ P_{GT} = ∅$). Notice that we analyze the reasons for false positives and false negatives in the submitted paper. These results demonstrate the capability of Tracer in finding patches accurately and completely.
Sensitivity Analysis
Tracer has two configurable parameters, i.e., the network depth limit in the first step of Tracer and the commit span in the third step. The default configuration is 5 and 30, which is used in the evaluation for RQ6, RQ7, RQ8 and RQ9. To evaluate the sensitivity of Tracer to the two parameters, we reconfigured one parameter and fix the other, and reran Tracer against our depth dataset. Specifically, the network depth limit was configured from 3 to 6 by a step of 1, and the commit span was configured from 0 to 60 by a step of 10.
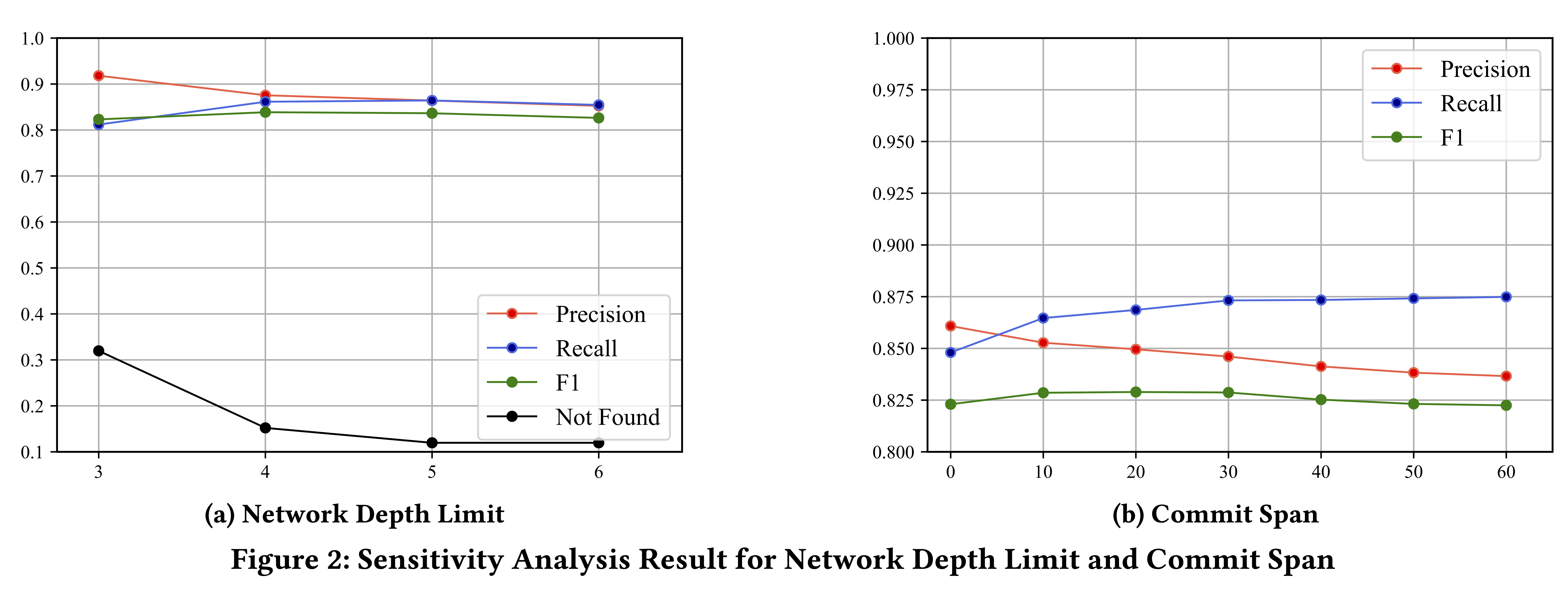
Fig. 2a and 2b show the impact of the two parameters on the accuracy of Tracer, where x-axis denotes the value of the parameter, and y-axis denotes the accuracy of Tracer. Overall, as the network depth limit increases, more potential patches are included in our reference network. The number of CVEs that Tracer finds no patch and precision decrease, and recall and F1-score first increase and then decrease. Hence, we believe 5 is a good value for the network depth limit. As the commit span increases, a wider scope of commits are searched. Precision decreases, recall increases, and F1-score first increases and then decreases. Notice that the number of CVEs Tracer finds no patch will not change and thus is not presented in Fig. 2b. Hence, we believe 30 is a good value for the commit span. These results indicate that the sensitivity of the accuracy of Tracer to the two configurable parameters is acceptable.
Application Analysis
Tracer is configurable to meet different accuracy requirements of applications. For applications that need high patch precision, Tracer can be configured to not construct the reference network in a layered way but simply use the direct references contained in the four advisory sources (i.e., skipping reference analysis in the first step). As shown by our ablation analysis in the submitted paper, this is actually the variant $v^5_1$ , and achieves the highest precision of 0.918, 6.3% higher than that of the original Tracer.
For applications that need high patch recall, Tracer can be configured to not follow the patch selection step in Tracer but select all patches in our reference network. As shown by our ablation analysis in the submitted paper, this is actually the variant $v^1_2$ , and achieves the highest recall of 0.940, 8.8% higher than that of the original Tracer.
These results demonstrate that the two variants of Tracer can meet the practical requirements of high precision and high recall.